微服务架构下的数据治理 构建灵活高效的数据处理与存储服务
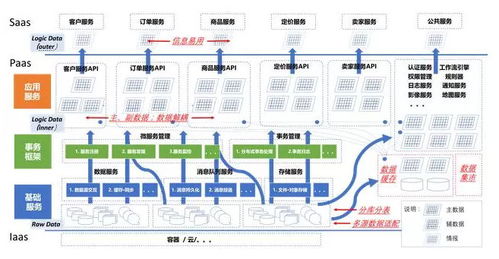
在微服务架构日益普及的今天,数据架构设计已不再是单一、集中的模式,而是逐步演变为分布式、去中心化的形态。微服务强调服务的独立性与自治性,这一理念同样深刻影响着数据处理与存储服务的设计。合理的数据架构不仅是系统性能的基石,更是确保业务敏捷性与数据一致性的关键。
微服务数据架构的核心挑战在于如何在服务自治与数据一致性之间取得平衡。传统的单体架构常采用共享数据库模式,但在微服务中,这种方式容易导致服务间耦合,违背了微服务设计的初衷。因此,领域驱动设计(DDD)中的“每个微服务拥有自己的数据库”原则被广泛采纳。这意味着每个服务管理其专属的数据存储,仅通过定义良好的API进行数据交互,从而实现技术栈的多样性与数据模型的独立性。
数据处理服务在微服务体系中扮演着“数据流水线”的角色。鉴于服务间数据不再直接共享,异步通信机制如消息队列(例如Kafka、RabbitMQ)变得至关重要。通过事件驱动架构,服务可以发布领域事件,其他服务订阅这些事件并更新自身的数据状态,实现最终一致性。例如,订单服务在创建订单后发布“OrderCreated”事件,库存服务监听到此事件后相应扣减库存,整个过程解耦且高效。对于复杂的数据处理需求,如实时分析或流处理,可以引入专门的数据处理微服务,利用Apache Flink或Spark Streaming等技术,构建独立的数据处理流水线,不影响核心业务服务的性能。
数据存储服务的选择则需遵循“根据用途选择数据库”的原则,即混合持久化模式。微服务允许每个服务根据其数据特性选择最合适的存储技术:用户配置服务可能使用文档数据库(如MongoDB)以灵活存储JSON结构;交易服务为保证ACID事务可能采用关系型数据库(如PostgreSQL);而实时推荐服务为高速读写或许会选用内存数据库(如Redis)。这种多样性虽然增加了运维复杂性,但通过容器化与自动化管理(如Kubernetes),可以有效地进行部署与监控。
分布式数据也带来了查询与一致性的难题。为解决跨服务查询问题,可采用API组合模式或命令查询职责分离(CQRS)。CQRS将读写操作分离,写模型处理业务逻辑并更新数据库,读模型则通过物化视图或专门的数据存储提供高效的查询服务,两者通过事件同步。 Saga模式是管理跨服务事务的经典方案,通过一系列本地事务和补偿动作,在分布式环境中维护业务一致性,避免传统的分布式事务带来的性能瓶颈。
数据安全与治理在微服务数据架构中不容忽视。每个服务应负责其数据的安全访问,通过API网关实施统一的认证与授权。数据隐私法规如GDPR要求数据可追溯与可删除,这需要在设计之初就考虑数据生命周期管理,例如在事件流中记录数据变更日志,以便实现审计与合规。
随着云原生技术的成熟,Serverless数据库与数据网格等新兴概念正在重塑微服务数据架构。数据网格强调数据作为产品,由领域团队全权负责,进一步将去中心化理念推向深入。对于开发团队而言,持续关注这些趋势,结合业务实际,才能构建出既灵活又可靠的数据处理与存储服务体系,最终支撑微服务架构在快速迭代中稳健运行。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/40.html
更新时间:2026-06-19 13:27:09