Google云计算三大核心技术 分布式数据处理MapReduce及其数据处理与存储服务
随着互联网数据量的爆炸式增长,传统的计算架构已难以应对海量数据的处理需求。在此背景下,Google作为云计算领域的先驱,提出并实践了多项开创性的技术,其中分布式数据处理MapReduce、数据处理与存储服务构成了其早期云计算核心技术体系的重要组成部分,为现代云计算和大数据处理奠定了坚实的基础。
1. 分布式数据处理MapReduce:海量计算的革命性框架
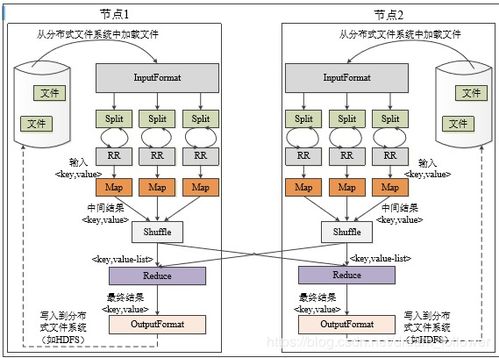
MapReduce是一种编程模型和相关的实现,用于大规模数据集(通常大于1TB)的并行计算。其核心思想源于函数式编程中的Map(映射)和Reduce(归约)操作,旨在简化分布式计算的复杂性,使开发者无需关注底层的任务调度、容错、数据分发等繁琐细节。
核心工作原理分为两个阶段:
1. Map(映射)阶段: 用户自定义一个Map函数,该函数处理输入的键值对,生成一组中间键值对。计算框架将输入数据自动分割成多个片段,并在大量计算节点上并行执行Map任务。
2. Reduce(归约)阶段: 用户自定义一个Reduce函数,该函数接收Map阶段输出的、具有相同“中间键”的所有“中间值”,并对它们进行合并、汇总或其他处理,最终生成最终的输出结果。框架会自动对中间结果进行排序和分发。
技术优势与影响:
- 高可扩展性: 通过增加普通商用服务器节点即可线性扩展计算能力,轻松处理PB级数据。
- 高容错性: 自动检测失败节点,并将失败节点上的计算任务重新调度到其他健康节点执行。
- 简化编程: 开发者只需关注业务逻辑(Map和Reduce函数),分布式系统的复杂性由框架处理。
MapReduce的开源实现Hadoop极大地推动了大数据产业的兴起,成为了大数据处理的代名词之一。
2. 数据处理与存储服务:GFS与Bigtable
MapReduce的高效运行离不开底层强大的数据存储与管理系统的支持。Google为此配套开发了另外两大核心技术。
A. 分布式文件系统GFS
GFS是专门为大规模、高并发访问和存储超大规模文件而设计的分布式文件系统。它运行在廉价的商用硬件集群上,提供了高可靠性、高可用性和高吞吐量的数据存储服务,是MapReduce的数据存储基石。
核心特点:
- 主从架构: 包含一个主服务器(Master)和多个块服务器(Chunk Server)。Master管理元数据,而实际的文件数据被分割成固定大小的“块”,分散存储在多个块服务器上。
- 高容错: 每个数据块默认会在三个不同的服务器上创建副本,确保硬件故障时数据不丢失、服务不间断。
- 为大文件优化: 针对搜索引擎场景下的大文件(如网页存档)进行优化,支持流式读取和追加写入。
B. 分布式结构化数据存储系统Bigtable
Bigtable是一个用于管理结构化数据的分布式存储系统,它被设计用来处理海量数据(PB级别),适用于从URL、网页内容到用户数据等多种Google服务。
核心特点:
- 稀疏的、分布式的、持久化的多维排序映射: 数据模型可以简单理解为一种“键值”存储,但其键是多维的(行键、列族、列限定符、时间戳),允许非常灵活和高效的数据布局。
- 高性能与高可扩展性: 数据按行键的字典序分片存储,支持动态增删节点以扩展容量和性能。
- 广泛适用性: 既支持低延迟的随机读写,也支持高效率的批量扫描,满足了从实时查询到批量处理的不同需求。
Bigtable的设计思想深刻影响了后续的NoSQL数据库,如HBase、Cassandra等。
三大技术的协同关系
GFS、MapReduce和Bigtable并非孤立存在,而是构成了一个协同工作的强大技术栈:
- GFS 作为底层存储,为MapReduce提供海量原始数据的持久化存储和高吞吐访问能力。
- MapReduce 作为计算引擎,可以高效地处理存储在GFS或Bigtable中的海量数据,进行复杂的批量计算和分析。
- Bigtable 作为结构化的存储服务,为需要快速随机访问和灵活数据模型的应用(如Web索引、Google Earth)提供支持,其本身也常作为MapReduce作业的输入源或输出目标。
与演进
Google提出的这三大核心技术(GFS, MapReduce, Bigtable)公开发表于2003至2006年的学术论文中,它们共同勾勒出了早期云计算基础设施的蓝图。它们解决了在超大规模集群上存储与计算的核心难题,即如何用廉价的商用硬件构建可靠、可扩展、高性能的系统。
尽管如今Google内部的技术栈已经迭代更新(例如用Colossus取代GFS,用Flume、MillWheel、Dataflow等更先进的模型补充或取代经典的MapReduce),但这些开创性的思想和技术设计原则——如分布式、容错、自动分片、简单编程模型——已经深深植根于现代云计算和大数据生态系统中,持续驱动着技术的发展。理解这三大核心技术,是理解当今云计算、大数据处理基石的关键一步。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/74.html
更新时间:2026-06-19 05:17:00