深入探讨MongoDB作为文件服务器 数据处理与存储机制解析
MongoDB作为文件服务器的可行性分析
1. MongoDB的存储引擎与文件存储
MongoDB本身并不专门设计为传统的文件服务器(如FTP或对象存储),但其GridFS规范使其能够有效地存储和管理大型文件。
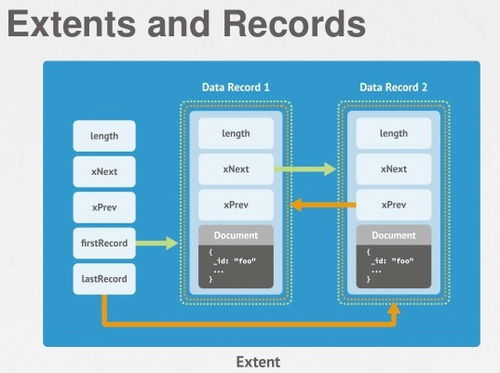
GridFS的核心机制:
- 将大文件分割成多个chunk(默认256KB)进行存储
- 使用两个集合:fs.files(存储元数据)和fs.chunks(存储二进制数据块)
- 支持分片集群,可实现海量文件存储
2. MongoDB的数据存储架构
2.1 存储引擎演化
- WiredTiger引擎(默认):支持文档级锁、压缩算法、快照隔离
- 存储结构:B+树索引,数据文件采用extent-based分配
2.2 物理存储格式
数据库 → 集合 → 文档(BSON格式)
↓
索引(B-tree)
↓
数据文件(.wt文件)3. 作为文件服务器的优势与局限
优势:
- 元数据与文件统一存储:文件属性可直接用JSON查询
- 自动分片扩展:适合分布式文件存储场景
- 事务支持:4.0版本后支持多文档ACID事务
- 丰富的查询能力:可对文件元数据进行复杂查询
局限性:
- 性能开销:相比专用对象存储(如MinIO),大文件吞吐效率较低
- 存储成本:二进制数据存储效率不如专用文件系统
- 功能局限:缺少文件版本控制、权限粒度控制等高级功能
4. 实际应用场景建议
适用场景:
- 需要强关联查询的文件和元数据(如用户上传的带丰富属性的媒体文件)
- 中小型文件(<16MB可直接存为BSON二进制,>16MB建议用GridFS)
- 开发测试环境快速原型搭建
不适用场景:
- 海量视频等超大文件存储
- 高并发静态文件服务
- 需要POSIX文件系统接口的场景
5. 性能优化策略
- 分片键设计:按文件创建时间或用户ID分片
- 索引优化:在
fs.files集合的查询字段建立索引 - 缓存配置:合理设置WiredTiger缓存大小
- 压缩选择:根据文件类型选择snappy/zlib压缩
6. 与专业文件存储方案对比
| 特性 | MongoDB GridFS | 对象存储(如S3) | 传统文件系统 |
|------|---------------|----------------|-------------|
| 元数据查询 | ★★★★☆ | ★★☆☆☆ | ★☆☆☆☆ |
| 横向扩展 | ★★★★☆ | ★★★★★ | ★★☆☆☆ |
| 大文件性能 | ★★☆☆☆ | ★★★★★ | ★★★★☆ |
| 成本效益 | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
7. 最佳实践建议
- 混合架构:关键元数据存MongoDB,实际文件存对象存储
- 大小阈值:16MB以下文件直接嵌入文档,以上使用GridFS
- 监控指标:重点关注chunk分布均衡性和存储引擎缓存命中率
- 备份策略:采用mongodump+文件系统快照的组合备份方案
###
MongoDB作为文件服务器在特定场景下具有独特价值,特别适合需要强数据关联性和灵活查询的应用程序。但对于纯大规模文件存储需求,建议采用混合架构或专业对象存储解决方案。随着MongoDB持续发展,其在文件处理领域的能力值得持续关注。
注:生产环境部署前,建议进行充分的性能测试和成本评估。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/75.html
更新时间:2026-06-19 22:16:04