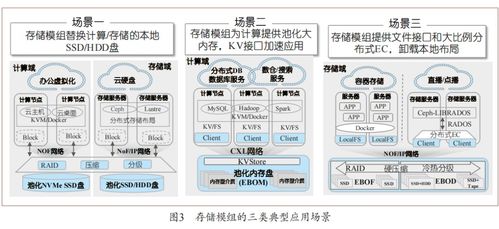
2017年中国大数据产业发展全景透视 数据处理与存储服务的核心地位与演进
2017年,中国大数据产业在政策持续驱动、技术迭代创新与市场需求爆发的多重作用下,进入了规模化应用与深度发展的关键阶段。其中,数据处理和存储服务作为整个大数据价值链的基石与核心环节,其发展态势直接反映了产业的成熟度与未来潜力。本文旨在梳理2017年中国大数据产业的发展脉络,并重点剖析数据处理与存储服务领域的关键进展、市场格局与技术趋势。
一、 2017年中国大数据产业宏观态势
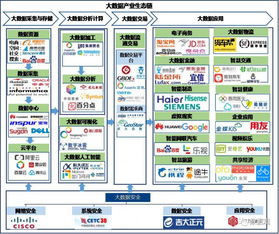
2017年,国家层面《大数据产业发展规划(2016-2020年)》进入全面落实期,各地方政府相继出台配套政策与行动计划,推动大数据在政务、工业、金融、健康医疗等领域的融合应用。产业规模持续高速增长,据相关研究机构数据,2017年中国大数据产业市场规模预计超过3500亿元人民币,同比增长约40%。产业生态日趋完善,形成了涵盖数据采集、存储、处理、分析、应用、安全等环节的完整产业链。
二、 数据处理服务的深化与平台化
数据处理服务是大数据从原始资源转化为可用资产的关键步骤。2017年,该领域呈现出以下显著特点:
- 实时化与流处理成为主流需求:随着物联网、移动互联网的普及,企业对实时数据分析和即时决策的需求激增。以Apache Flink、Spark Streaming为代表的流计算框架受到广泛关注和应用,数据处理模式从传统的批量(Batch)处理加速向流批一体(Stream-Batch Integration)演进。
- 平台化与云服务化加速:企业自建复杂数据处理体系的成本与门槛高企,促使数据处理服务向平台化(PaaS)和云服务(DaaS、数据湖/仓即服务)转型。阿里云、腾讯云、华为云等主要云厂商提供了从数据集成、数据开发、数据治理到数据服务的一站式数据处理平台,极大降低了企业应用大数据的初始成本和技术难度。
- 数据治理与质量管理意识觉醒:“垃圾进,垃圾出”的困境促使企业开始重视数据治理。2017年,数据血缘追踪、元数据管理、数据质量监控等工具和服务需求开始凸显,数据处理服务的内涵从单纯的“加工”扩展到“治理”与“增值”。
三、 数据存储服务的多元化与分层化
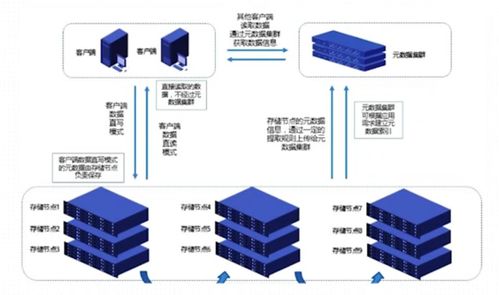
海量、多源、异构数据的存储是产业发展的物理基础。2017年,数据存储服务呈现出技术路线多元化与存储架构分层化的清晰趋势。
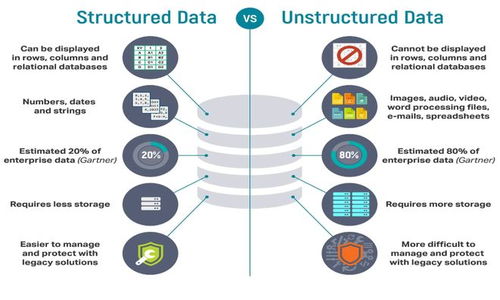
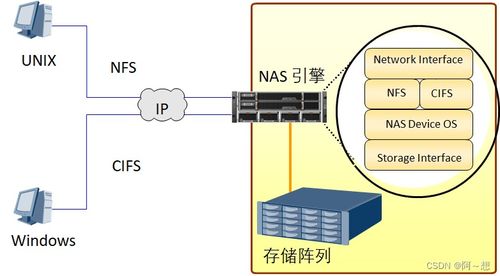
- 存储技术百花齐放:传统的关系型数据库(RDBMS)在事务处理场景仍不可或缺,但面对非结构化、半结构化数据,NoSQL数据库(如MongoDB、HBase、Cassandra)、NewSQL数据库以及分布式文件系统(如HDFS)已成为标准配置。特别是基于内存的计算与存储(如Redis)在高速读写的实时场景应用广泛。
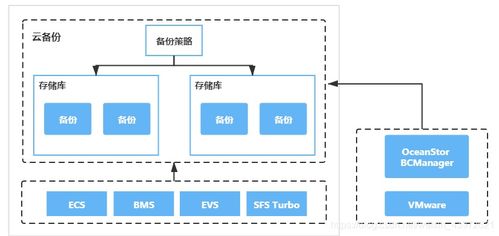
- 云存储占据主导地位:公有云提供的对象存储(如阿里云OSS、腾讯云COS)因其近乎无限的扩展性、高可靠性和极低的存储成本,已成为海量冷/温数据备份、归档以及互联网内容存储的首选。混合云存储架构也成为许多大中型企业的务实选择,兼顾了公有云的弹性与私有云的安全性。
- 分层存储架构成熟:根据数据的访问频率、价值密度和性能要求,业界普遍采用“热-温-冷”的分层存储策略。热数据(实时处理)通常存放于内存或高速SSD,温数据(日常分析)存放于高性能磁盘或分布式数据库,冷数据(合规备份、历史归档)则迁移至成本更低的磁带库或对象存储。这种分层策略在2017年得到广泛应用,实现了成本与效率的最优平衡。
四、 核心驱动力与未来展望
2017年数据处理与存储服务的快速发展,主要得益于云计算基础设施的普及、人工智能(尤其是机器学习)对高质量数据集的渴求,以及各行业数字化转型的迫切压力。
数据处理与存储服务将更紧密地结合:
- 智能融合:存储系统将集成更多数据预处理和初步分析功能(计算存储融合),数据处理平台则会更智能地调度和利用异构存储资源。
- 安全与隐私增强:随着《网络安全法》的实施,数据存储的加密、脱敏、访问控制以及数据处理过程中的隐私保护技术(如差分隐私、联邦学习)将成为服务的标准配置和核心竞争力。
- 边缘协同:物联网的深入发展将推动数据处理与存储向边缘侧延伸,形成“云-边-端”协同的新型数据处理与存储架构。
总而言之,2017年是中国大数据产业,特别是数据处理与存储服务,从概念走向务实、从孤立走向协同、从单一技术走向综合解决方案的关键一年。其发展不仅夯实了产业基础,也为后续的数据价值挖掘与智能应用爆发铺平了道路。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/69.html
更新时间:2026-06-19 10:17:05